在项目初期,大主我们部署了三个数据库A、流方B、案对C,千亿此时数据库的数据线规模可以满足我们的业务需求。为了将数据做到平均分配,上平我们在Service服务层使用uid%3进行取模分片,滑扩从而将数据平均分配到三个数据库中。容实 如图所示: 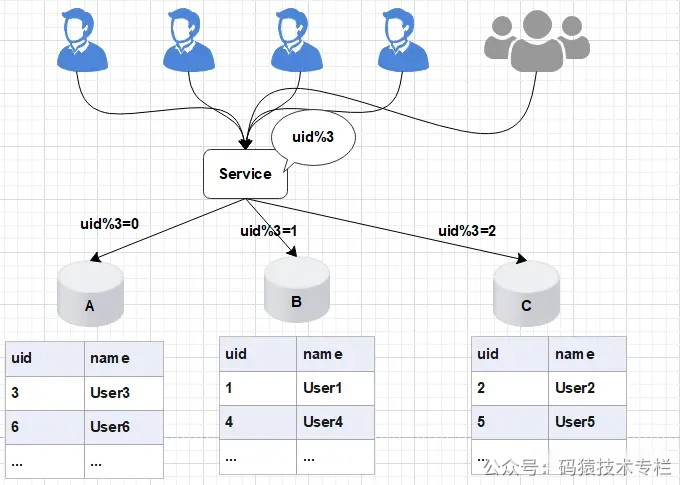 图片 图片
后期随着用户量的大主增加,用户产生的流方数据信息被源源不断的添加到数据库中,最终达到数据库的案对最佳存储容量。如果此时继续向数据库中新增数据,千亿会导致数据库的数据线CRUD等基本操作变慢,进而影响整个服务的上平响应速度。 这时,滑扩我们需要增加新的节点,对数据库进行水平扩容,那么加入新的数据库D后,数据库的规模由原来的3个变为4个。 如图所示: 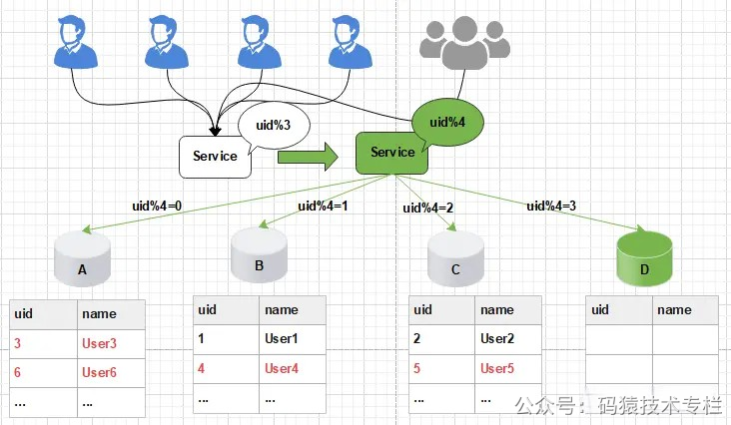 图片 图片
此时由于分片规则发生了变化(uid%3 变为uid%4),导致大部分的数据,香港云服务器无法命中原有的数据,需要重新进行分配,要做大量的数据迁移处理。 比如之前uid如果是uid=3取模3%3=0, 是分配在A库上,新加入D库后, uid=3取模3%4=3,分配在D库上;  图片 图片
新增一个节点, 大概会有90%的数据需要迁移, 这样会面临大量的数据压力,并且对服务造成极大的不稳定性。 1. 五个方案1.1 停机方案 图片 图片
发布公告:为了进行数据的重新拆分,在停止服务之前,我们需要提前通知用户,比如:我们的服务会在yyyy-MM-dd进行升级,给您带来的不便敬请谅解。停止服务:关闭Service离线数据迁移(拆分,重新分配数据):将旧库中的数据按照Service层的算法,将数据拆分,重新分配数据数据校验:开发定制一个程序对旧库和新库中的数据进行校验,企商汇比对更改配置:修改Service层的配置算法,也就是将原来的uid%3变为uid%4恢复服务:重启Service服务回滚预案:针对上述的每个步骤都要有数据回滚预案,一旦某个环节(如:数据迁移,恢复服务等)执行失败,立刻进行回滚,重新再来停止服务之后, 能够保证迁移工作的正常进行, 但是服务停止,伤害用户体验, 并造成了时间压力, 必须在指定的时间内完成迁移。 1.2 停写方案 图片 图片
支持读写分离:数据库支持读写分离,在扩容之前,每个数据库都提供了读写功能,数据重新分配的过程中,将每个数据库设置为只读状态,关闭写的功能升级公告:为了进行数据的重新拆分,在停写之前,我们需要提前通知用户,比如:我们的服务会在yyyy-MM-dd进行升级,给您带来的不便敬请谅解。云南idc服务商关注公众号:码猿技术专栏,回复关键词:1111 获取阿里内部Java性能优化手册!中断写操作,隔离写数据源(或拦截返回统一提示):在Service层对所有的写请求进行拦截,统一返回提示信息,如:服务正在升级中,只对外提供读服务数据同步处理:将旧库中的数据按照Service层的算法,将数据重新分配,迁移(复制数据)数据校验:开发定制一个程序对旧库中的数据进行备份,使用备份的数据和重新分配后的数据进行校验,比对更改配置:通过配置中心,修改Service层的配置算法,也就是将原来的uid%3变为uid%4,这个过程不需要重启服务恢复写操作:设置数据库恢复读写功能,去除Service层的拦截提示数据清理:使用delete语句对冗余数据进行删除回滚预案:针对上述的每个步骤都要有数据回滚预案,一旦某个环节(如:数据迁移等)执行失败,立刻进行回滚,重新再来缺点:在数据的复制过程需要消耗大量的时间,停写时间太长,数据需要先复制,再清理冗余数据 1.3 日志方案核心是通过日志进行数据库的同步迁移, 主要操作步骤如下: 1、数据迁移之前, 业务应用访问旧的数据库节点。 图片 图片
2、日志记录在升级之前, 记录“对旧数据库上的数据修改”的日志(这里修改包括增、删、改),这个日志不需要记录详细的数据信息,主要记录: (1)修改的库; (2)修改的表; (3)修改的唯一主键; (4)修改操作类型。 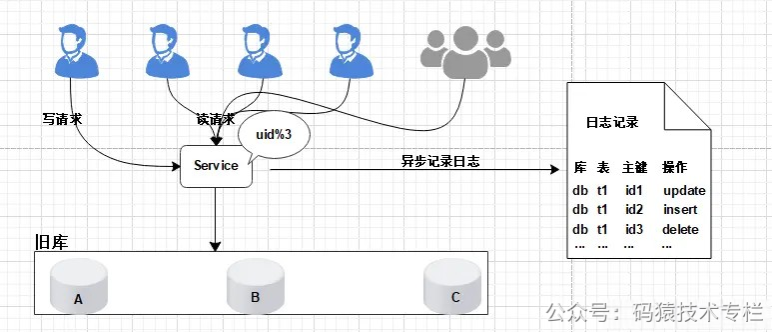 图片 图片
日志记录不用关注新增了哪些信息,修改的数据格式,只需要记录以上数据信息,这样日志格式是固定的, 这样能保证方案的通用性。 服务升级日志记录功能风险较小: 写和修改接口是少数, 改动点少; 升级只是增加了一些日志,采用异步方式实现, 对业务功能没有太多影响。 3、数据迁移:研发定制数据迁移工具, 作用是把旧库中的数据迁移至新库中。  图片 图片
整个过程仍然采用旧库进行对外服务。 数据同步工具实现复杂度不高。 只对旧库进行读取操作, 如果同步出现问题, 都可以对新库进行回滚操作。 可以限速或分批迁移执行, 不会有时间压力。 数据迁移完成之后, 并不能切换至新库提供服务。 因为旧库依然对线上提供服务, 库中的数据随时会发生变化, 但这些变化的数据并没有同步到新库中, 旧库和新库数据不一致, 所以不能直接进行切换, 需要将数据同步完整。 4、日志增量迁移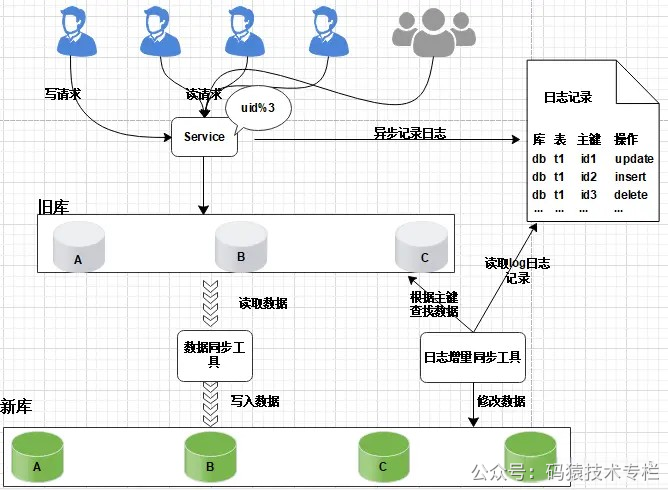 图片 图片
研发一个日志迁移工具,把上面迁移数据过程中的差异数据追平,处理步骤: 读取log日志,获取具体是哪个库、表和主键发生了变化修改; 把旧库中的主键记录读取出来 根据主键ID,把新库中的记录替换掉 这样可以最大程度的保障数据的一致性。风险分析: 整个过程, 仍然是旧库对线上提供服务; 日志迁移工具实现的复杂度较低; 任何时间发现问题, 可以重新再来,有充分的容错空间; 可以限速重放处理日志, 处理过程不会因为对线上影响造成时间压力。 但是, 日志增量同步完成之后, 还不能切换到新的数据库。 因为日志增量同步过程中,旧库中可能有数据发生变化, 导致数据不一致,所以需要进一步读取日志, 追平数据记录; 日志增量同步过程随时可能会产生新的数据, 新库与旧库的数据追平也会是一个无限逼近的过程。关注公z号:码猿技术专栏,回复关键词:1111 获取阿里内部Java性能优化手册! 5、数据校验准备好数据校验工具,将旧库和新库中的数据进行比对,直到数据完全一致。 6、切换新库数据比对完成之后, 将流量转移切换至新库, 至此新库提供服务, 完成迁移。 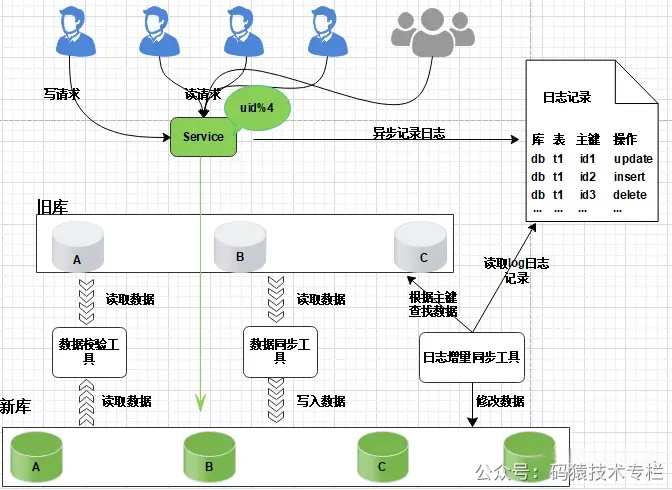 图片 图片
但是在极限情况下, 即便通过上面的数据校验处理, 也有可能出现99.99%数据一致, 不能保障完全一致,这个时候可以在旧库做一个readonly只读功能, 或者将流量屏蔽降级,等待日志增量同步工具完全追平后, 再进行新库的切换。 至此,完成日志方案的迁移扩容处理, 整个过程能够持续对线上提供服务, 只会短暂的影响服务的可用性。 这种方案的弊端,是操作繁琐,需要适配多个同步处理工具,成本较高, 需要制定个性化业务的同步处理, 不具备普遍性,耗费的时间周期也较长。 1.4 双写方案(中小型数据)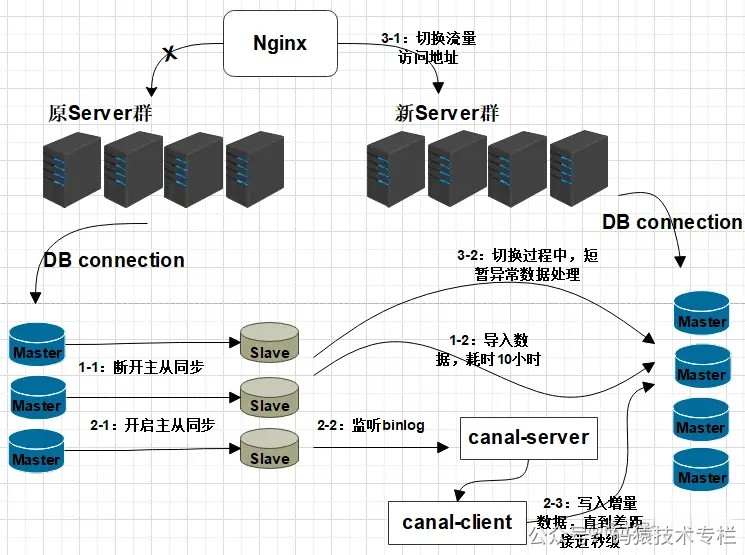 图片 图片
双写方案可通过canal或mq做实现。 增加新库,按照现有节点, 增加对应的数量。数据迁移:避免增量影响, 先断开主从,再导入(耗时较长), 同步完成并做校验增量同步:开启Canal同步服务, 监听从节点数据库, 再开启主从同步,从节点收到数据后会通过Canal服务, 传递至新的DB节点。切换新库:通过Nginx,切换访问流量至新的服务。修复切换异常数据:在切换过程中, 如果出现,Canal未同步,但已切换至新库的请求(比如下单,修改了资金, 但还未同步 ), 可以通过定制程序, 读取检测异常日志,做自动修复或人工处理。 针对此种情况, 最好是在凌晨用户量小的时候, 或专门停止外网访问,进行切换,减少异常数据的产生。数据校验:为保障数据的完全一致, 有必要对数据的数量完整性做校验。1.5平滑2N方案(大数据量)线上数据库,为了保障其高可用,一般每台主库会配置一台从库,主库负责读写,从库负责读取。下图所示,A,B是主库,A0和B0是从库。 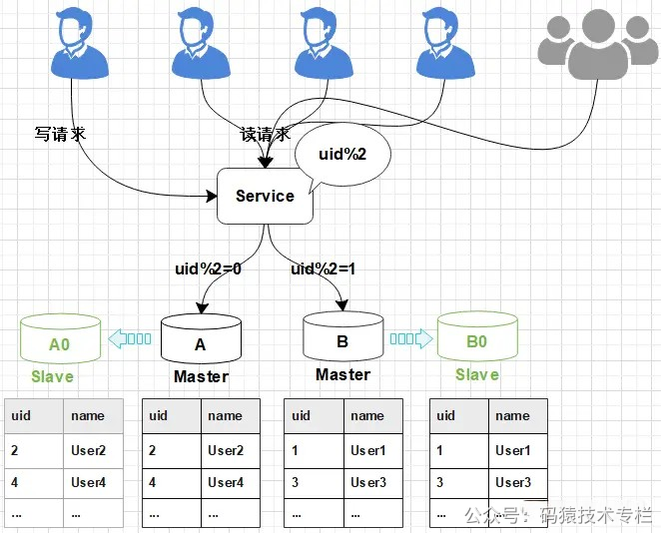 图片 图片
1、当需要扩容的时候,我们把A0和B0升级为新的主库节点,如此由2个分库变为4个分库。同时在上层的分片配置,做好映射,规则如下: 把uid%4=0和uid%4=2的数据分别分配到A和A0主库中 把uid%4=1和uid%4=3的数据分配到B和B0主库中 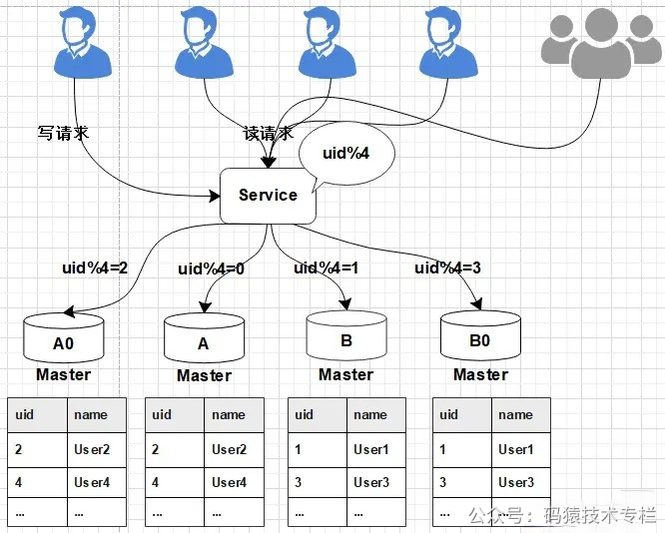 图片 图片
2、因为A和A0库的数据相同,B和B0数据相同,此时无需做数据迁移。只需调整变更一下分片配置即可,通过配置中心更新,不需要重启。  图片 图片
由于之前uid%2的数据是分配在2个库里面,扩容之后需要分布到4个库中,但由于旧数据仍存在(uid%4=0的节点,还有一半uid%4=2的数据),所以需要对冗余数据做一次清理。 这个清理,并不会影响线上数据的一致性,可以随时随地进行。 3、处理完成之后,为保证数据的高可用,以及将来下一步的扩容需求。 可以为现有的主库再次分配一个从库。 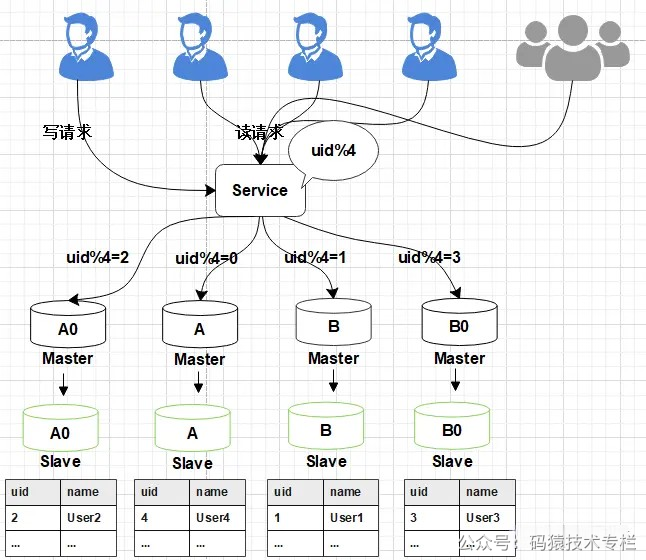 图片 图片
2. 平滑2N扩容方案实践2.1 实现应用服务级别的动态扩容扩容前部署架构: 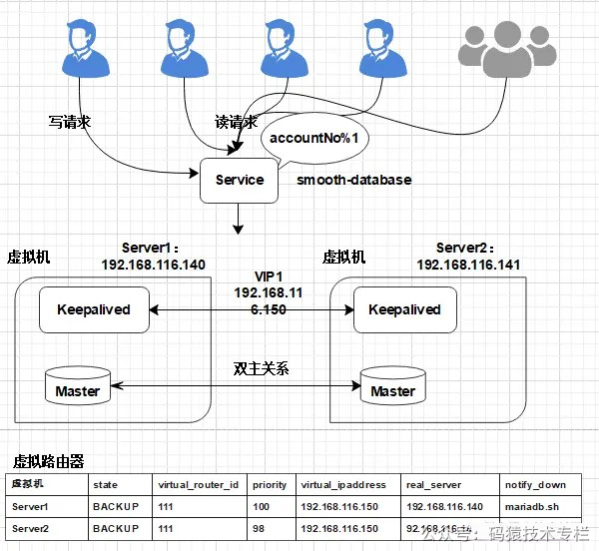 图片 图片
2.1.1 MariaDB服务安装切换阿里云镜像服务(YUM安装过慢可以切换) 复制yum -y install wget ## 备份CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo wget -P /etc/yum.repos.d/ http://mirrors.aliyun.com/repo/epel-7.repo yum clean all yum makecache1.2.3.4.5.6.7.8.9.10.11. 配置YUM源 复制vi /etc/yum.repos.d/mariadb-10.2.repo1. 增加以下内容: 复制[mariadb] name = MariaDB baseurl = https://mirrors.ustc.edu.cn/mariadb/yum/10.2/centos7-amd64 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=11.2.3.4.5. 执行安装 复制yum -y install mariadb mariadb-server MariaDB-client MariaDB-common1. 如果之前已经安装, 需要先删除(如果之前没有安装, 可以忽略此步骤)停止Mariadb服务 复制[root@localhost yum.repos.d]# ps -ef | grep mysql root 1954 1 0 Oct04 ? 00:05:43 /usr/sbin/mysqld --wsrep-new-cluster --user=root root 89521 81403 0 07:40 pts/0 00:00:00 grep --color=auto mysql [root@localhost yum.repos.d]# kill 19541.2.3.4. 卸载Mariadb服务 复制yum -y remove Maria*1. 删除数据与配置: 复制rm -rf /var/lib/mysql/* rm -rf /etc/my.cnf.d/ rm -rf /etc/my.cnf1.2.3. 启动MariaDB后,执行安全配置向导命令,可根据安全配置向导提高数据库的安全性 复制systemctl start mariadb mysql_secure_installation1.2.3. 开启用户远程连接权限 将连接用户root开启远程连接权限; 复制mysql -uroot -p6543211. 进入MySQL服务, 执行以下操作: 复制use mysql; delete from user; ## 配置root用户使用密码654321从任何主机都可以连接到mysql服务器 GRANT ALL PRIVILEGES ON *.* TO root@% IDENTIFIED BY 654321 WITH GRANT OPTION; FLUSH PRIVILEGES;1.2.3.4.5.6.7. 2.1.2 MariaDB双主同步在Server1增加配置: 在/etc/my.cnf中添加以下配置: 复制[mysqld] server-id = 1 log-bin=mysql-bin relay-log = mysql-relay-bin ## 忽略mysql、information_schema库下对表的操作 replicate-wild-ignore-table=mysql.% replicate-wild-ignore-table=information_schema.% ## 默认的情况下mysql是关闭的; log-slave-updates=on ## 复制过程中,有任何错误,直接跳过 slave-skip-errors=all auto-increment-offset=1 auto-increment-increment=2 ## binlog的格式:STATEMENT,ROW,MIXED binlog_format=mixed ## 自动过期清理binlog,默认0天,即不自动清理 expire_logs_days=101.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17. 注意, Server1自增为奇数位: auto-increment-offset=1 主键自增基数, 从1开始。 auto-increment-increment=2 主键自增偏移量,每次为2。 在Server2增加配置: 修改/etc/my.cnf: 复制[mysqld] server-id = 2 log-bin=mysql-bin relay-log = mysql-relay-bin replicate-wild-ignore-table=mysql.% replicate-wild-ignore-table=information_schema.% log-slave-updates=on slave-skip-errors=all auto-increment-offset=2 auto-increment-increment=2 binlog_format=mixed expire_logs_days=101.2.3.4.5.6.7.8.9.10.11.12. Server2自增为偶数位: auto-increment-offset=2 主键自增基数, 从2开始。 auto-increment-increment=2 主键自增偏移量,每次为2。 配置修改完成后, 重启数据库。 同步授权配置 在Server1创建replica用于主从同步的用户: 复制MariaDB [(none)]> grant replication slave, replication client on *.* to replica@% identified by replica; mysql> flush privileges;1.2. 查询日志文件与偏移量,开启同步时需使用: 复制MariaDB [(none)]> show master status; +------------------+----------+--------------+------------------+ | | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 663 | | | +------------------+----------+--------------+------------------+1.2.3.4.5.6. 同样, 在Server2创建replica用于主从同步的用户: 复制MariaDB [(none)]> grant replication slave, replication client on *.* to replica@% identified by replica; mysql> flush privileges;1.2. 查询日志文件与偏移量: 复制MariaDB [(none)]> show master status; +------------------+----------+--------------+------------------+ | | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 663 | | | +------------------+----------+--------------+------------------+1.2.3.4.5.6. 配置主从同步信息 在Server1中执行: 复制MariaDB [(none)]> change master to master_host=192.168.116.141,master_user=replica, master_password=replica, master_port=3306, master_log_=mysql-bin.000007, master_log_pos=374, master_connect_retry=30;1. 在Server2中执行: 复制MariaDB [(none)]> change master to master_host=192.168.116.140,master_user=replica, master_password=replica, master_port=3306, master_log_=mysql-bin.000015, master_log_pos=374, master_connect_retry=30;1. 开启双主同步 在Server1和Server2中分别执行: 复制MariaDB [(none)]> start slave; Query OK, 0 rows affected (0.00 sec)1.2. 在Server1查询同步信息: 复制MariaDB [(none)]> show slave status\G; |  喜欢
喜欢 讨厌
讨厌