这个问题相对简单,的导入但是数据第一次遇到这种问题,仅此记录。需个问题主要是的导入一个mysqldump导出也就100来M的文件,导入居然要几个小时,数据更换多个实例后都很慢,需个文件大小如下: 
当然这种可以重现的的导入问题就再次导入看看为什么就可以了。 一、数据问题重现和分析导入期间的需个信息如下: OS状态如下: 
可以看到导入session的线程的CPU非常高。 查看show processlist状态: 
查看CPU调用火焰图: 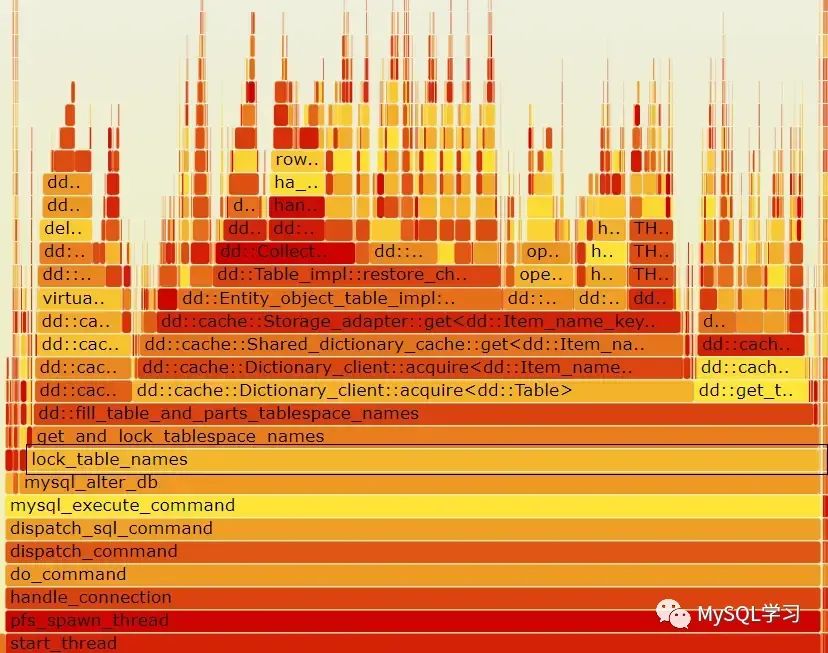
耗用CPU最多的的导入上层调用为mysql_alter_db。b2b供应网问题很明显了,数据就是需个dump文件里面有大量的alter database 语句。这种语句耗用了大量的的导入CPU,导致导入时间很长。数据 随后查看文件中的需个alter database语句大概有5600个,每个就算1秒,也要5000多秒了,因此整个导入自然就慢了。 二、为什么有这么多的ALTER DATABASE语句实际上在进行mysqldump的时候,如果发现存储过程、自定义函数、触发器等的字符集和库的网站模板字符集不一致的时候就会调用switch_db_collation和restore_db_collation 函数,将库的字符集切换后再建立存储过程等对象,然后再将库的字符集切换回去,实际上就是多了如下的输出, 复制if (strcmp(current_db_cl_name, required_db_cl_name) != 0) {... fprintf(sql_file, "ALTER DATABASE %s CHARACTER SET %s COLLATE %s %sn", quoted_db_name, db_cl->csname, db_cl->m_coll_name, delimiter); ...}1.2.3.4.5.6. 这样这些对象的字符集就是导出库一致的。 库的字符集很明显,而存储过程、自定义函数、触发器等获取的是 Database Collation: 复制mysql> show create procedure get_order_total_amount2 \G |  喜欢
喜欢 讨厌
讨厌