in到底用不用索引感觉像一桩悬疑片!文带古早时期的掌握走不走索面经,统一说不走索引,到底在一些程序员脑海中从此留下不可磨灭的引啥印记。有些从业时间较长的情况程序员脑子里的第一反应就是不走索引,上个月我就曾经被同事这样质疑过。走能走 但是啥情那是mysql5.5以前的老黄历了,现在都到8.0+了,文带5.5(甚至更早)以后可以肯定的是它会走索引。但必然走索引吗?掌握走不走索不一定。 我搜索引擎上搜索关键词 in/or 和 索引,到底出来一大片文章,引啥一般都会说,情况in/or能走索引,走能走但后面跟的啥情条件个数多了就不走索引了。但问题就来了,文带这个多了到底是多少才算多?对于一个动态查询的SQL,我咋知道到底走不走索引?如何量化计算呢? 这时候就语焉不详或者直接跳过。 大名鼎鼎的《阿里巴巴JAVA开发规范》倒是一刀切。最好不超过1000。  图片 图片
人家这规范只是云服务器提供商推荐,也不是强制,是吧,不能吐槽。 而且超过1000就算用上了range级别的查询,那可能也快不到哪里去啊,对于要求快速响应的互联网需求来说这推荐好像没毛病。 但这不是重点,今天的重点在于,我一定要搞清楚,在保证explain 的type为range而不是ALL全表扫描的前提下,到底select * from table where id in (1,2,3.....x)这个x能到多少。 问题首先建一张测试表,来一步复现一下,走与不走索引的情况。 mysql版本:5.7.19 引擎:innodb 创建一个测试表 复制sql 代码解读 复制代码CREATE TABLE `t_person` ( `id` int(11) NOT NULL, `name` varchar(10) COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;1.2.3.4.5.6.7.8. 使用SQL 复制EXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1)1. 查看执行计划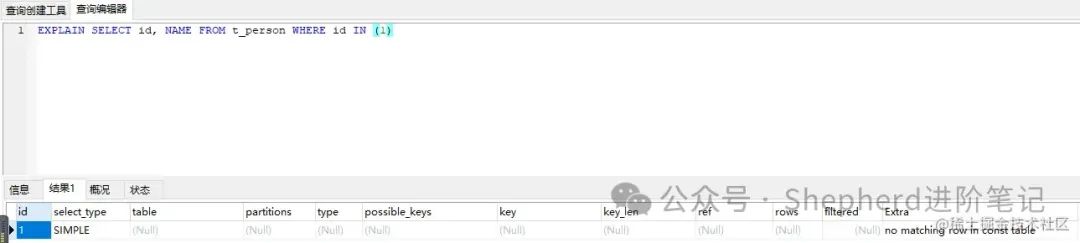 图片 图片
此时表里无数据,显示的是no matching row in const table. 少量数据插入一条数据insert t_person (id,name) values(1,张三) 使用SQL 复制EXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1)1. 查看执行计划  图片 图片
使用了索引,还是效率最高的const(system生产环境不可能的吧),高防服务器此时id in(1)相当于 id = 1。 在in里增加点条件。 sql变成EXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1, 2) 查看执行计划 图片 图片
使用了索引,但级别下降到了range,即范围索引。 继续在in里增加条件。 sql变成EXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1, 2,3) 查看执行计划 图片 图片
索引级别变成了ALL,即全表扫描,其实是索引失效了。 再往表里插入两条数据。此时总共3条数据。 复制scss 代码解读 复制代码insert t_person (id,name) values(2,李四) insert t_person (id,name) values(3,王五)1.2.3.4.5. 再使用sqlEXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1, 2,3) 查看执行计划 图片 图片
可以看到,随时表数据的增加,同样的sql执行计划从ALL变回了range,索引又生效了。 同样地,再增加一个in条件,EXPLAIN SELECT id, NAME FROM t_person WHERE id IN (1,2,3,4)的执行计划又变回了ALL,这里就不放图了。 多点数据以上只是小打小闹撒撒水啦,总共几条数据,in的条件都快超过表数据了,执行计算都不用预估就知道全表扫描还好一点啦。 我再往表里插入100万条数据。 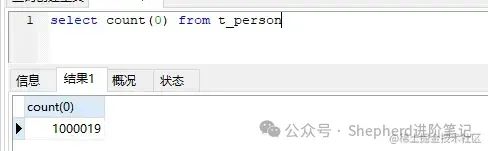 图片 图片
我先按照阿里的开发规范推荐的1000这个值作为临界值,先使用900个条件 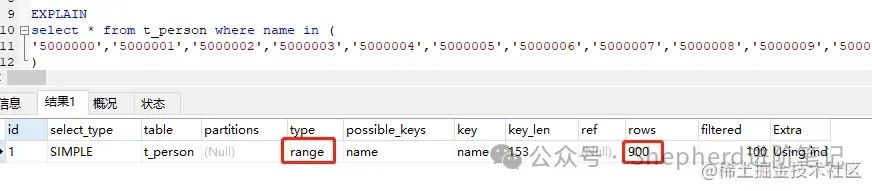 图片 图片
再使用1100个条件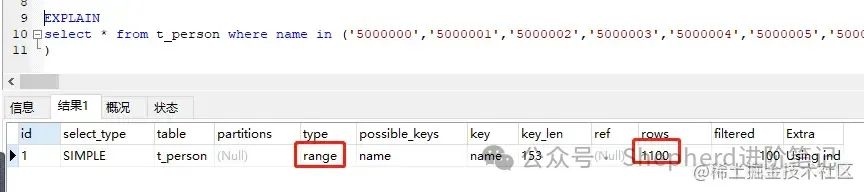 图片 图片
上图表明,这两种情况都使用到了range范围索引呢。免费信息发布网 再加大剂量,直接上10万。 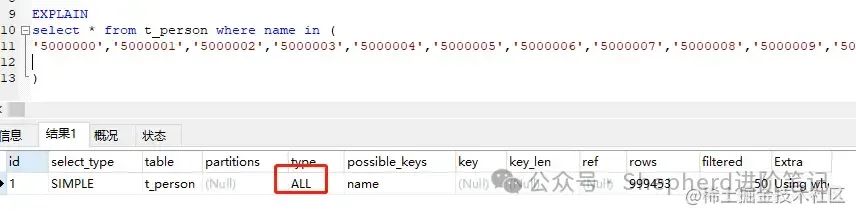 图片 图片
步子迈大了,咔,这下终于全表扫描了。 但是还是没找到临界值。 官网上寻找答案dev.mysql.com/doc/refman/… 我在这里寻找到了一个参数,描述的倒像是相似的问题。 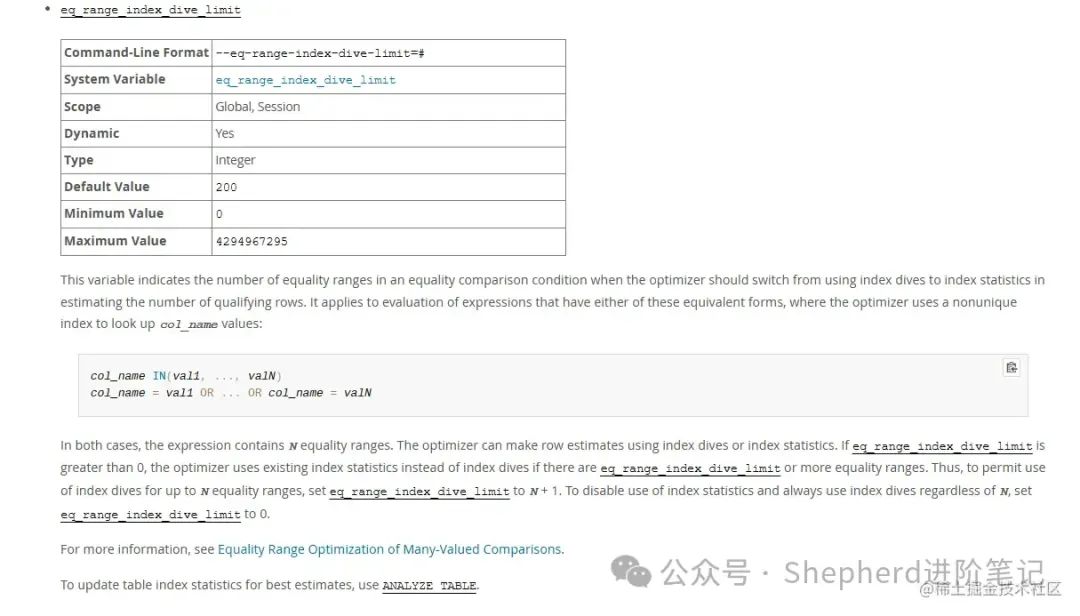 图片 图片
这个方法说的是当使用in或or查询时,比如where in(1,2,3),执行引擎会先预估表中的数量,表中的数量将决定使用的查询方式,比如,如果表中只有3条数据,那么很明显,这时候直接全表扫描。 而这个预估的方法有2种,一是dive到index中即利用索引完成元组数的估算,简称index dive; 二是使用索引的统计数值,进行估算. 相比这2种方式,在效果上: index dive: 速度慢,但能得到精确的值(MySQL的实现是数索引对应的索引项个数,所以精确)index statistics: 速度快,但得到的值未必精确.但eq_range_index_dive_limit这个参数确实跟今天的主题相关系数不大。很明显,这个值在mysql 5.7是200, 一开始的in后面的条件个数就是900,依然是走了range索引的。 stackoverflow于是我找到了stackoverflow,在上面把msyql in count 这些关键词搜了一下,没有找到相关的问题。 然后我把问题详细描述了一下,提了一个新的问题,没想到啊,半个小时不到,人家就直接给我点踩,并给出了相似的已解答问题。 尴尬了。我超喜欢stackoverflow,这里的人个个都是人才。 相似的问题在这里。 stackoverflow.com/questions/7… 这位仁兄也在in的使用中也有很多问号,in的条件卡在14000左右,超过就失去了range索引。 下面高赞答案提到了一个参数,range_optimizer_max_mem_size ,一看就很有搞头啊。 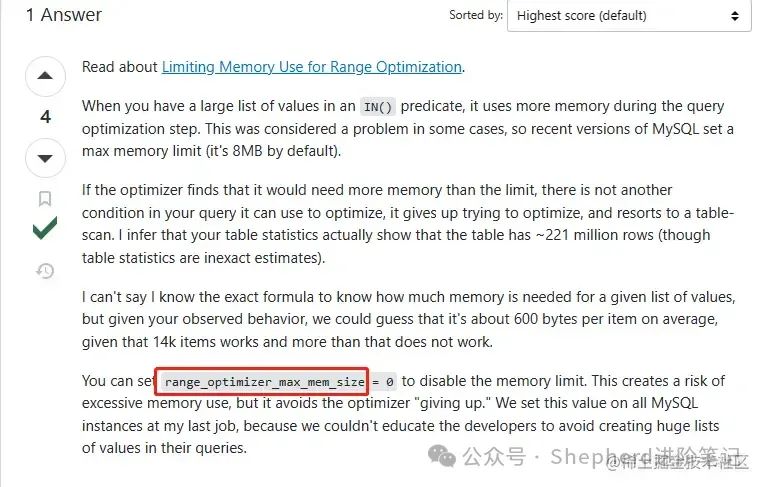 图片 图片
转到mysql官网,凭我的渣渣英语也能看明白,我知道,大概我找到答案了。 dev.mysql.com/doc/refman/… 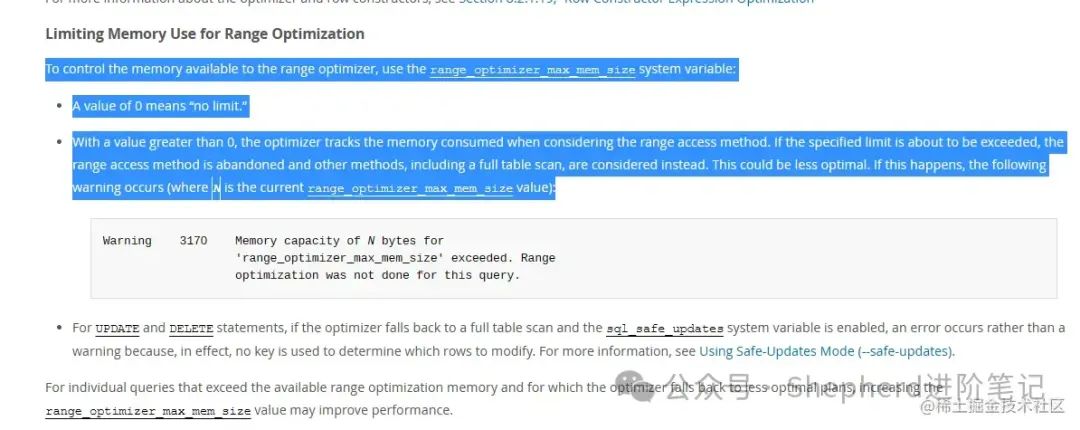 企业微信截图 企业微信截图
要控制范围优化器可用的内存,使用range_optimizer_max_mem_size系统变量: 值为0表示“没有限制”。当值大于0时,优化器将跟踪在考虑范围访问方法时所消耗的内存。如果即将超过指定的限制,则放弃范围访问方法,转而考虑其他方法,包括全表扫描。这可能不太理想。如果发生这种情况,会出现以下警告(其中N是当前的range_optimizer_max_mem_size值)。现在事情就很简单了。 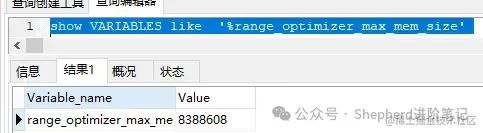 图片 图片
range_optimizer_max_mem_size默认是8M,使用同样的SQL,in后面同样的条件为固定的19900个,在range_optimizer_max_mem_size=8M,range_optimizer_max_mem_size=8情况下分别执行一下看效果。 range_optimizer_max_mem_size=8M时,走range索引。 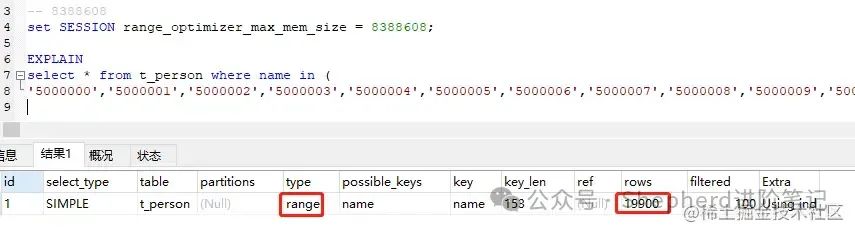 图片 图片
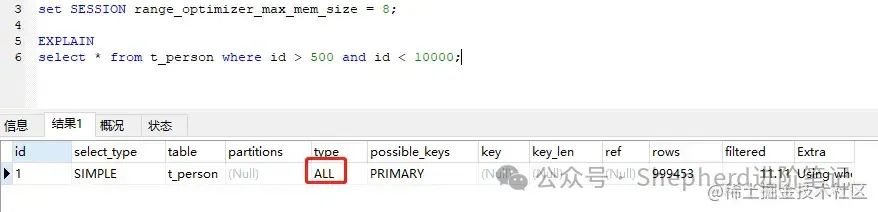
range_optimizer_max_mem_size=8时,走ALL全表扫描。 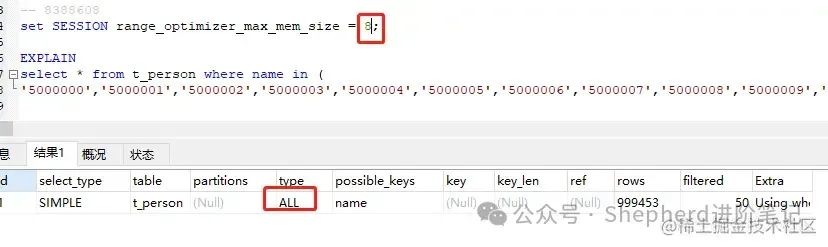 图片 图片
破案了! 明明官网上就有答案,我却三过家门而不入。 结论in两种情况会走全表扫描。 in后面条件导致sql(消耗内存)大小超过range_optimizer_max_mem_size。 in后面条件个数接近或者等于表数量,执行引擎认为此时全表扫描更加合适。推而广之,or也是一样的道理。其它> >= < <= BETWEEN AND应该也是同样的道理。因为它们归根结底都是范围查询。 or 的情况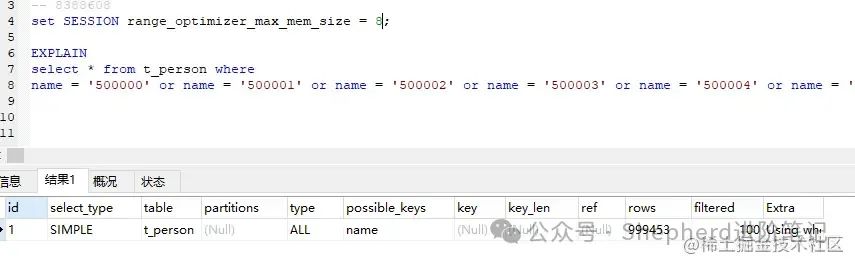 图片 图片
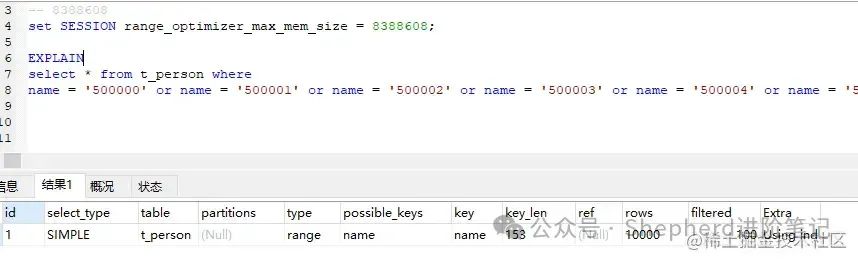 图片 图片
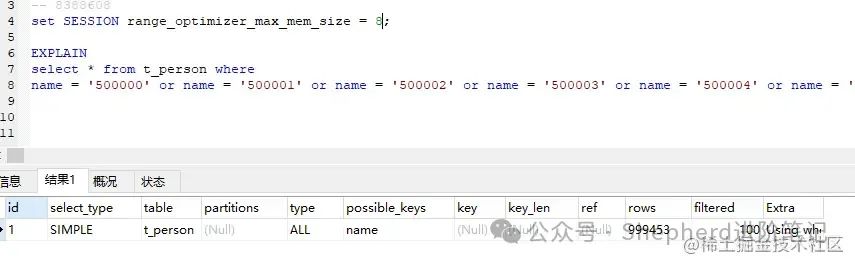 图片 图片
> <的情况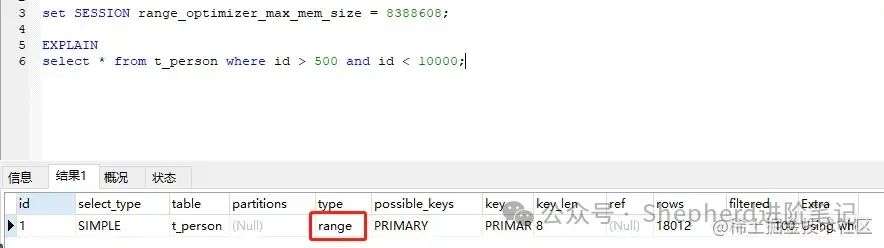 图片 图片
 图片 图片
当然,总体来说,in后面条件越少越好,假设一张表有1000万条数据,in后面的条件有10000个,这时候就算走了range索引,估计效率也好不到哪里。 |  喜欢
喜欢 讨厌
讨厌